回路分割の必要性はあるか
このセクションでは、回路の分割が本当に必要かどうか、または HIL 構成の変更などの他のソリューションを検討する必要があるかどうかを判断する方法について説明します。
- 回路内のコンバータが多すぎるため、コンバータの総重量が制限を超えています。
- 回路内の接触器が多すぎます- 接触器の総数が制限を超えています
- マトリックスメモリの過負荷- 最も一般的には回路内のスイッチの数が多いことが原因です
- シミュレーションの時間ステップが大きすぎます
これらのリソース制限を考慮する必要がある実際のケースの補足的なデモンストレーションは、ビデオ ナレッジベースおよびHIL 基礎コースの一部としても利用できます。
回路内のコンバータが多すぎる
回路の分割を実行する最も一般的な理由の 1 つは、モデル内のコンバータが多すぎることです。コンバータは重みによって特徴付けられます。プロセッシング コアは通常、重み 3 までのコンバータ (3 相コンバータなど) をサポートしますが、構成 4 の HIL604 (C4) など、重み 4 までのコンバータをサポートするプロセッサ構成もあります。図 1に示すサンプル モデルには、昇圧コンバータ (重み = 1) と 3 相コンバータ (重み = 3) が存在します。これは、パワー エレクトロニクス コンバータ全体の重みが 4 であることを意味します。この回路が HIL604 C1 用にコンパイルされると、コンバータ全体の重みが制限を超えているというエラーがコンパイラによって報告されます。一見すると回路を 2 つのコアに分割せざるを得ないように思えますが、代わりに HIL604 C4 に切り替えて、回路を分割せずにこの問題を解決することができます。場合によっては、回路を分割するよりも構成を変更する方がよいこともあります。 HIL604 C1 と HIL604 C4 の両方用にコンパイルされた同じモデルのコンパイラ レポートを図 2に示します。
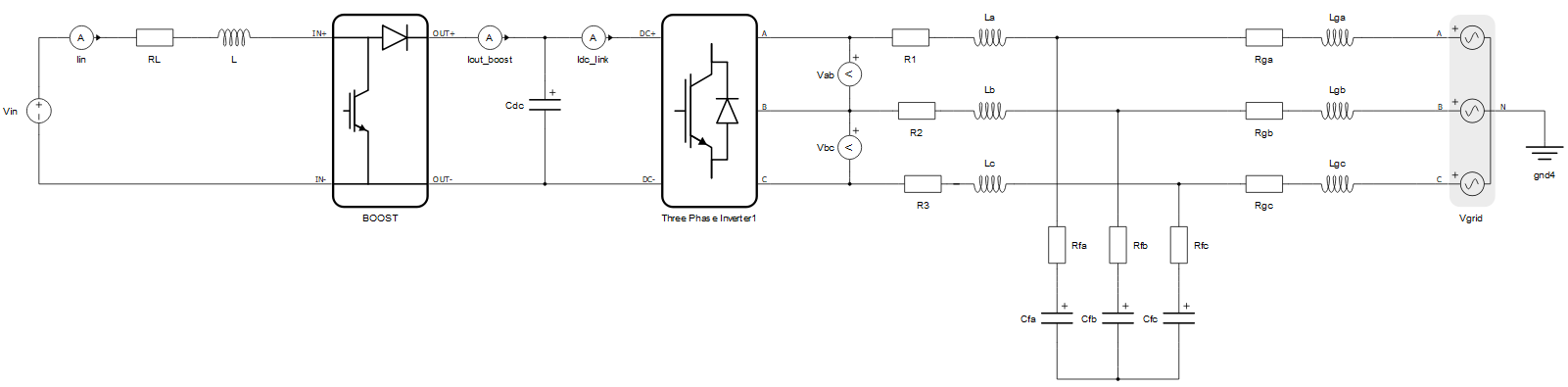

モデル内に複数のコンバータが存在するもう一つの例として、図3に示す三相バックツーバックコンバータが挙げられます。モデル内のコンバータの総重量は6です。単一コアあたり最大重量6のコンバータをサポートするHIL構成は存在しないため、このモデルでは回路分割を行う必要があります。
回路内の接触器が多すぎる
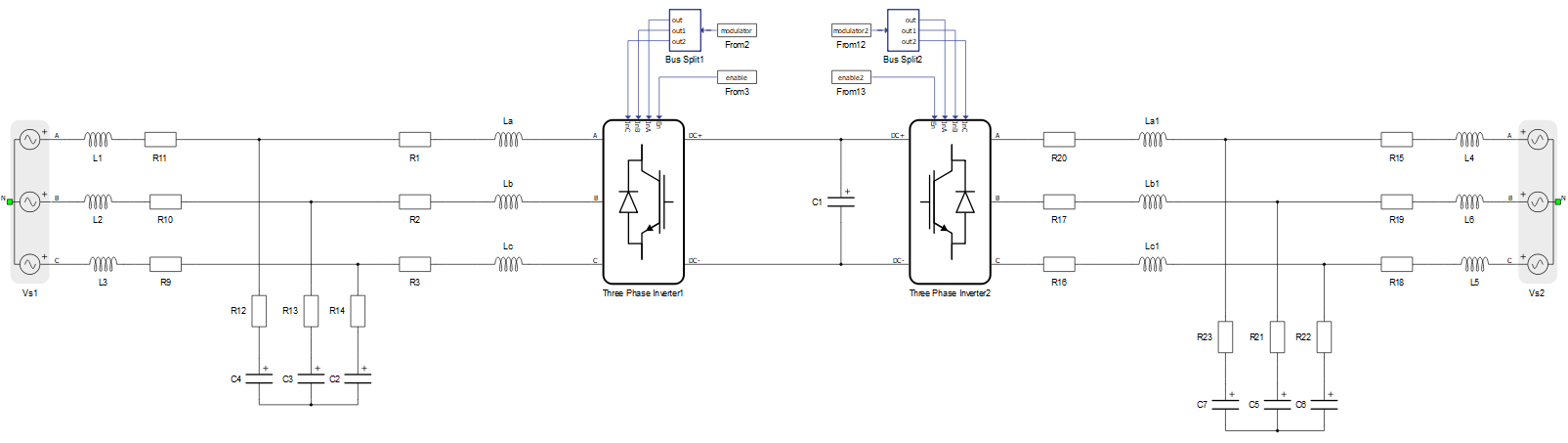
すべてのデバイス構成において、コアあたりにサポートされる理想的なコンタクタの数は6です。コンタクタの数がこの数を超える場合、回路の分割は避けられません。これは通常、多数の保護デバイスと回路遮断器が存在するマイクログリッドモデルで発生します。7つのコンタクタを持つモデルの例を図4に示します。
マトリックスメモリの過負荷
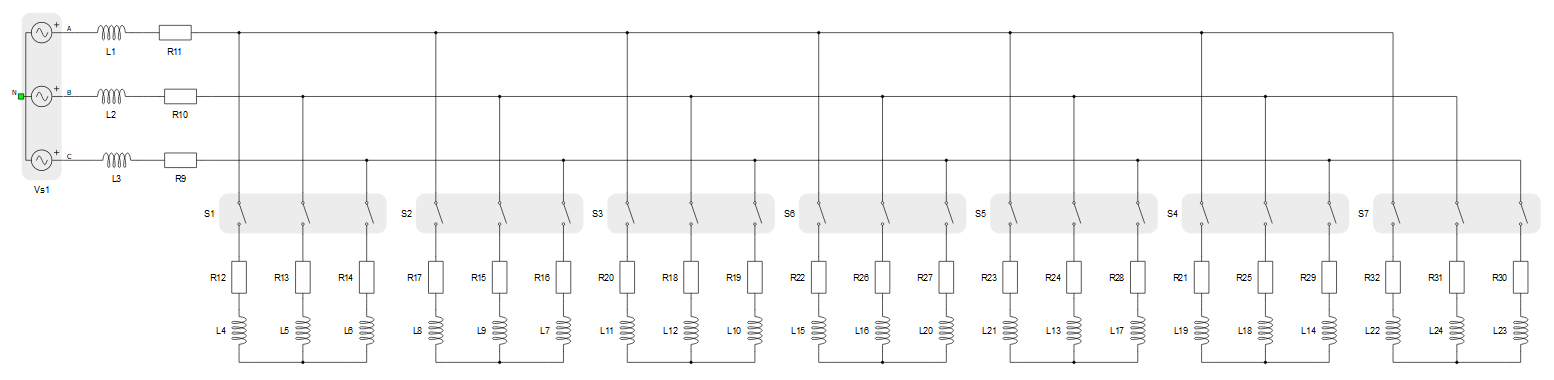
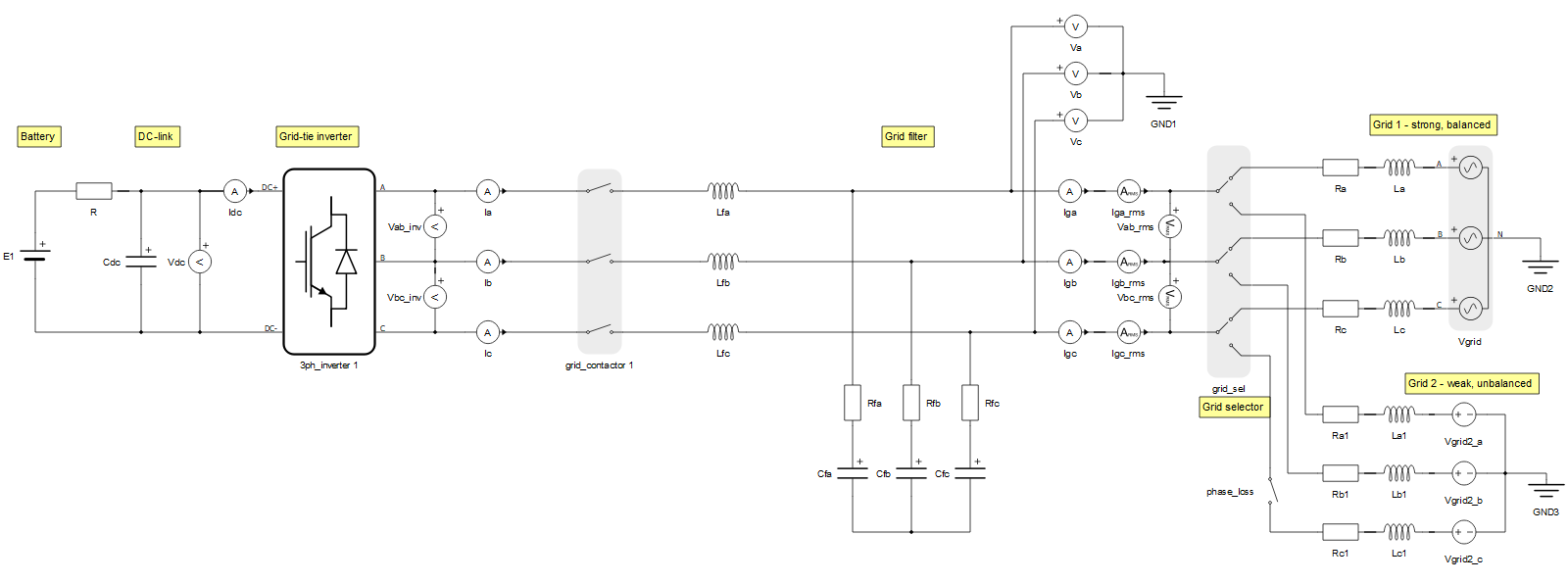
図 5の例では、ハードウェア リソースのいずれも過負荷になっていないように見えます。接触器の数は 6 未満で、コンバータ全体の重量は 3 です。ただし、モデルが HIL604 C1 用にコンパイルされると、図 7の左側に示すように、コア 1 のマトリックス メモリ使用率が 269% であることを示すエラー メッセージが報告されます。図 6に示すようにモデルを分割することが、この問題を解決する 1 つの方法です。これにより、1μs のシミュレーション時間ステップで 2 つのコアで実行されるモデルが作成されます。ただし、この場合は、HIL604 構成を C4 に変更すると、回路を分割せずに問題を解決できます。HIL604 C4 のコンパイラ レポートを図 7の右側に示します。

シミュレーションの時間ステップが大きすぎます
回路を分割することで、計算が複数のコアやデバイスに分散され、シミュレーション速度を低下させることができます。これは、Example Explorerの IEEE 13 ノードバスのサンプルモデルで実証できます。現在、このモデルは 4μs の固定タイムステップで実行されています。2つのコアに分割すれば、1μs で実行できます。